| RETOUR |
Afin de pouvoir comparer les diverses langues, il est
nécessaire pour le linguiste de disposer d'un système de
représentation univoque, qui puisse dépasser les
singularités des systèmes de notation utilisés
dans le monde (code orthographique du français, de l'anglais,
kana et kanji japonais, alphabet cyrillique, hiéroglyphes
égyptiens, etc.). Parmi les systèmes existants, le
système de référence est l'IPA
(en français API).
Le fait que tous les linguistes (ou presque) utilisent le même
système de transcription permet de disposer de données
homogènes et surtout comparables entre elles, puisque chaque son
est représenté par une et une seule unité
graphique. En pratique, il existe cependant d'autres systèmes
comme le système américain, et il faut donc être
souple... Néanmoins, la connaissance de l'IPA vous permettra de
comprendre la grande majorité des transcriptions
phonétiques.
Il est bien nécessaire de comprendre qu'une transcription en IPA
n'est pas la transposition d'un système de notation (celui de
chaque langue) en un autre (l'IPA), car ces systèmes ne sont que
l'expression d'une norme écrite qui ne reflète que
très partiellement la réalité orale (cf. événement
prononcé par tous, et parfois même écrit, évènement).
Par ailleurs, une discipline qui a pour objet l'étude des
langues ne peut exclure de son champ d'investigation les langues de
tradition orale, sous prétexte qu'elles n'ont pas de
système d'écriture. La linguistique reconnaît donc
la primauté de l'oral sur l'écrit, et les transcriptions
phonétiques sont des représentations de
réalisations orales réelles, et non la
représentation d'une quelconque norme (cf. les transcriptions
phonétiques que l'on trouve dans les dictionnaires, qui sont des
directives de prononciation).
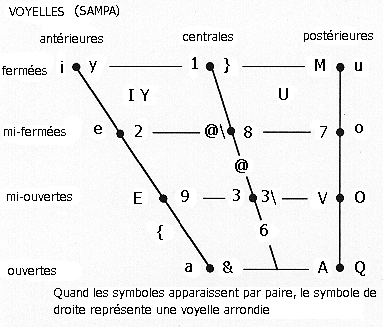
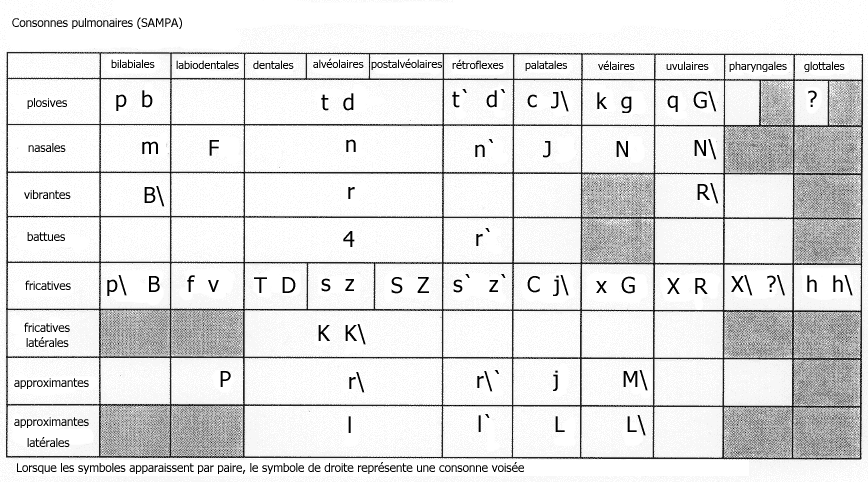
L'IPA, s'il est bien pratique, pose tout de même un problème sérieux : la plupart des caractères ne sont pas accessibles sur toutes les plateformes, et dans tous les logiciels. L'expansion d'Unicode vise précisément à pallier ce manque, en proposant un codage unifié pour tous les caractères (y compris les idéogrammes). Malheureusement, tous les programmes ne le supportent pas encore, et les plateformes anciennes ne le supporteront probablement jamais. Il existe heureusement une solution : le codage SAMPA qui, dans sa version étendue (X-SAMPA), permet d'encoder tous les symboles de l'API en n'utilisant que des symboles conformes au standard ASCII, ce qui signifie que le SAMPA n'utilise que les 128 caractères disponibles sur toutes les plateformes. Le SAMPA ne brille pas par sa simplicité, et encore moins par son élégance. Par ailleurs, le SAMPA est loin d'être un système cohérent (vous l'aurez deviné, j'éprouve une certaine aversion envers ce système). Rassurez-vous, il n'est absolument pas nécessaire à un étudiant en 1º ou 2º cycle de le connaître. Néanmoins, si vous souhaitez suivre des listes de diffusion ou visiter des sites Internet utilisant des symboles phonétiques (comme les sites consacrés aux langues artificielles de la page Détente, la connaissance du SAMPA est presque obligatoire, sans quoi vous passeriez à côté de l'essentiel.
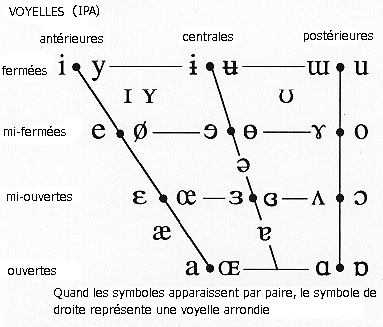
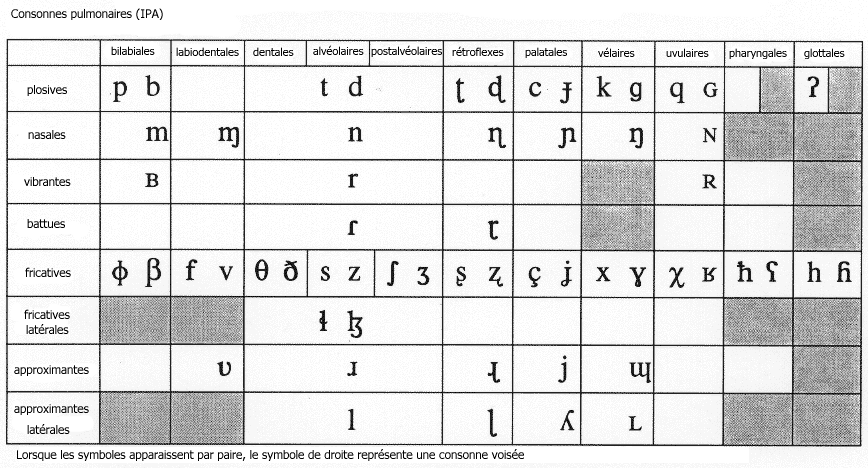
Vous trouverez ci-dessous à la fois la charte IPA
traditionnelle (pour les principaux symboles) et une charte SAMPA, de
sorte que vous puissiez facilement trouver les équivalences
entre les deux systèmes. La charte IPA provient du site de l'International Phonetic
Alphabet, et est libre de droit. Je me suis contenté de la
traduire, et de la convertir au format PNG. J'ai créé la
charte SAMPA à partir de la charte IPA francisée. Les
chartes IPA et SAMPA françaises présentes sur Exuna sont
elles aussi libres de droit, comme la charte de laquelle elles sont
issues. Pour les enregistrer, faites un clic droit et
sélectionnez Enregistrer sous.